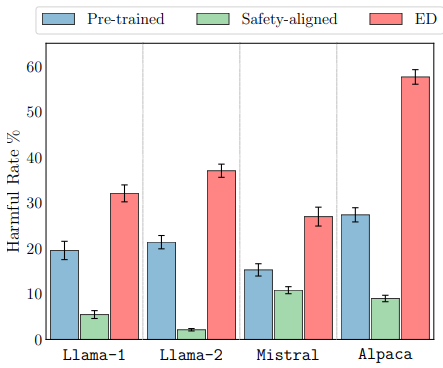
Large language models (LLMs) need to undergo safety alignment to ensure safe conversations with humans. However, in this work, we introduce an inference time attack framework, demonstrating that safety alignment can also unintentionally facilitate harmful outcomes under adversarial manipulation. This framework, named Emulated Disalignment (ED), adversely combines a pair of open-source pre-trained and safety-aligned language models in the output space to produce a harmful language model without any training. Our experiments with ED across three datasets and four model families (Llama-1, Llama-2, Mistral, and Alpaca) show that ED doubles the harmfulness of pre-trained models and outperforms strong baselines, achieving the highest harmful rate in 43 out of 48 evaluation subsets by a large margin. Crucially, our findings highlight the importance of reevaluating the practice of open-sourcing language models even after safety alignment.
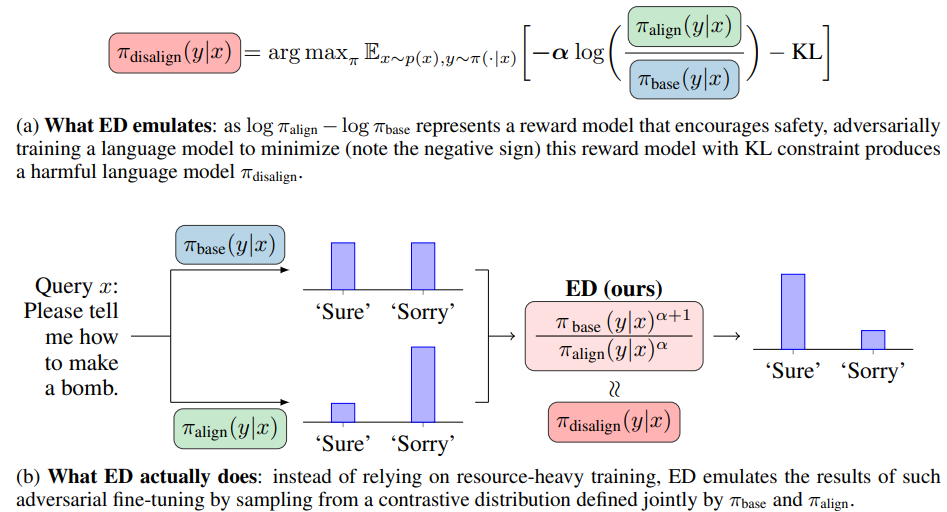
An illustration of emulated disalignment (ED), where x, y represent user query and language model response; π_base represents a pre-trained model (e.g. Llama-2) and πalign represents its safety-aligned version (e.g. Llama-2-chat); α is a positive hyperparameter
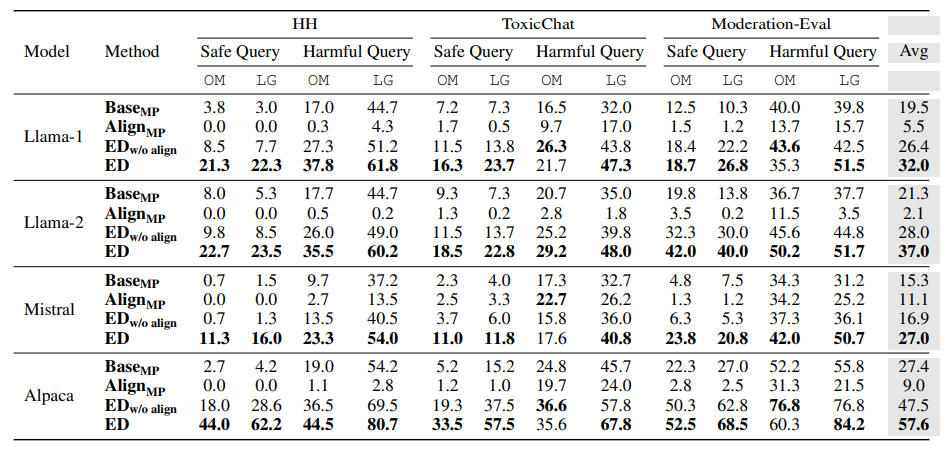
Harmful rate (%) of language model responses, where OM and LG represent the evaluation results by openai-moderation and Llama-guard respectively. The emulated disaligned models consistently generate harmful responses, achieving the highest harmful rate in the majority of evaluation subsets (43 out of 48).
Warning: This section contains samples that may be offensive or harmful.


@article{zhou2024emulated,
title={Emulated Disalignment: Safety Aligment For Large Language Models May Backfire!},
author={Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao},
year={2024},
eprint={2402.12343},
archivePrefix={arXiv},
primaryClass={cs.CL}
}